Building Yantra: A Visual Workflow Automation Engine
Nov 2, 2025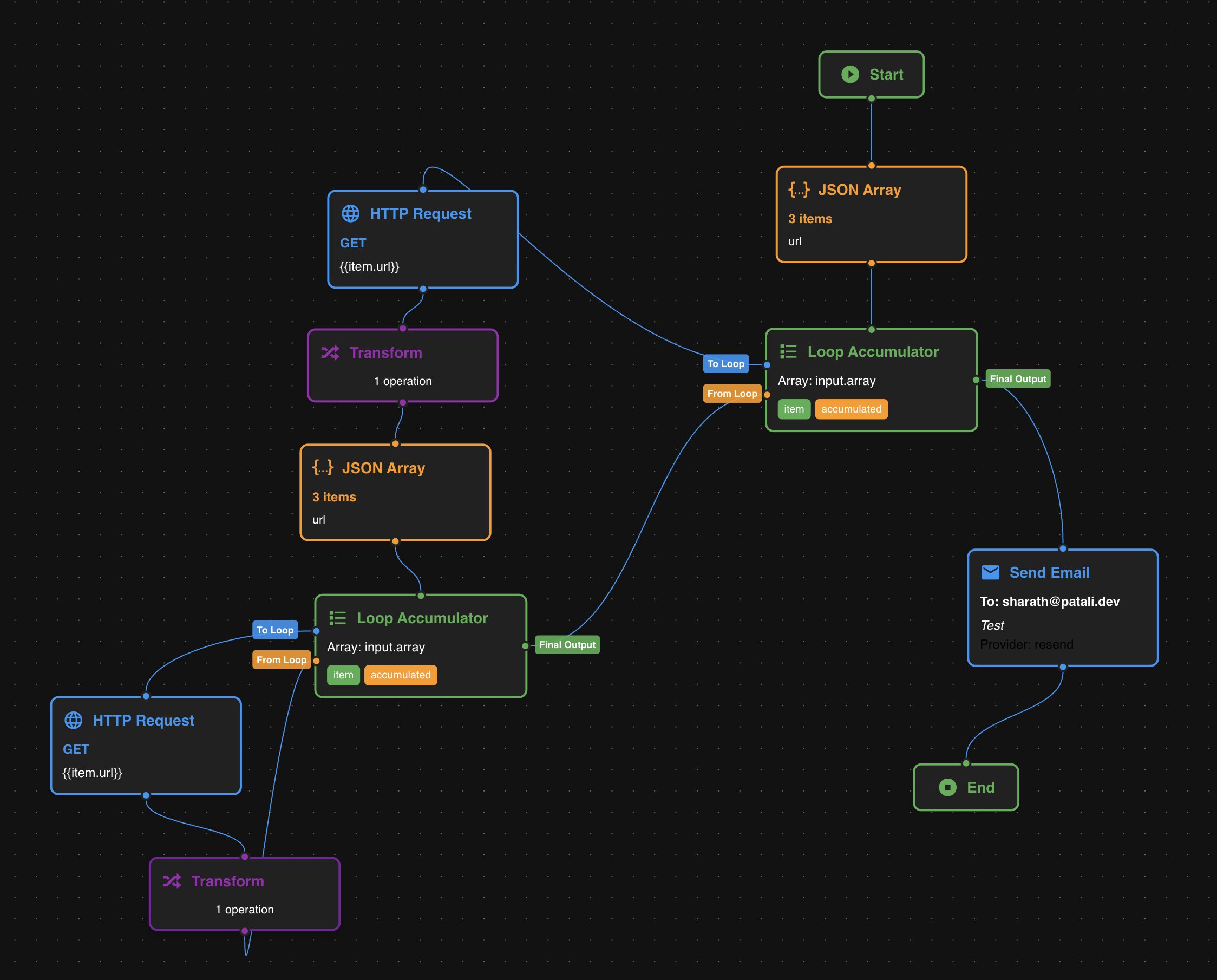
The Inspiration: From Cartoons to media processing libraries to Real Problems
Growing up, I was fascinated by Tom’s and Wile E. Coyote’s elaborate contraptions that set up impossibly complex chain reactions. The end result was usually Jerry or the Road Runner outwitting them, but it wasn’t the fault of the machine itself. I even attempted a few times to set up my own Rube Goldberg machine. I was thinking the other day that I find some DevOps tasks fun for exactly the same reason. The magic is how the chain comes together and ultimately produces some result. It’s fun to see the chain reaction in action.
The other major inspiration came from GStreamer, the multimedia framework. A long time ago, I used it to build a speech recognition system for PyMT. The Unix-like, elegant pipes architecture fascinated me back then. For instance take this gstreamer command:
gst-launch-1.0 filesrc location=input.mp4 ! decodebin ! videoconvert ! x264enc ! mp4mux ! filesink location=output.mp4
Each component (filesrc, decodebin, videoconvert) does one thing. Data flows through a pipeline. Components are reusable. The whole is greater than the sum of its parts.
This pipeline architecture is brilliant for the same reason Rube Goldberg machines are: complexity through composition.
The Real Problem: Scattered DevOps Scripts
But the actual trigger for building Yantra was frustration. Real, frustration.
I was working on multiple projects where I’d repeatedly need to:
- Pull data from various APIs
- Transform and aggregate it
- Generate reports
- Send notifications to Slack or email
For each project, I’d write bespoke scripts:
fetch_bitbucket_pipeline_stats.shweekly_report.shslack_alert_monitor.sh
Each script was mostly glue code. Each had its own error handling, retry logic, and scheduling mechanism. Each lived in a different repo (sometimes even without repos). When something broke, it was quite a bit of overhead to find and fix things. I was repeating the same pattern again and again. Plus, I didn’t want to do things manually that a machine could do. I like being lazy!
So I thought: What if instead of writing scripts, I could just visually compose a workflow? Drag an HTTP node, connect it to a Transform node, route that to a Conditional node, which branches to either Email or Slack?
That’s what Yantra became: a visual workflow builder for the DevOps scripts I was tired of rewriting. At least that’s how it started; it’s transforming into a more generic tool as I started building it!
The Architecture: Building a Workflow Engine
1. The Visual Workflow Builder
The frontend is built with Vue.js and React Flow, providing a drag-and-drop canvas where you can:
- Drag nodes from a palette (HTTP, Transform, Email, Slack, etc.)
- Connect them by drawing edges between ports
- Configure each node through property panels
- Check input/output and errors from all nodes in their execution runs.
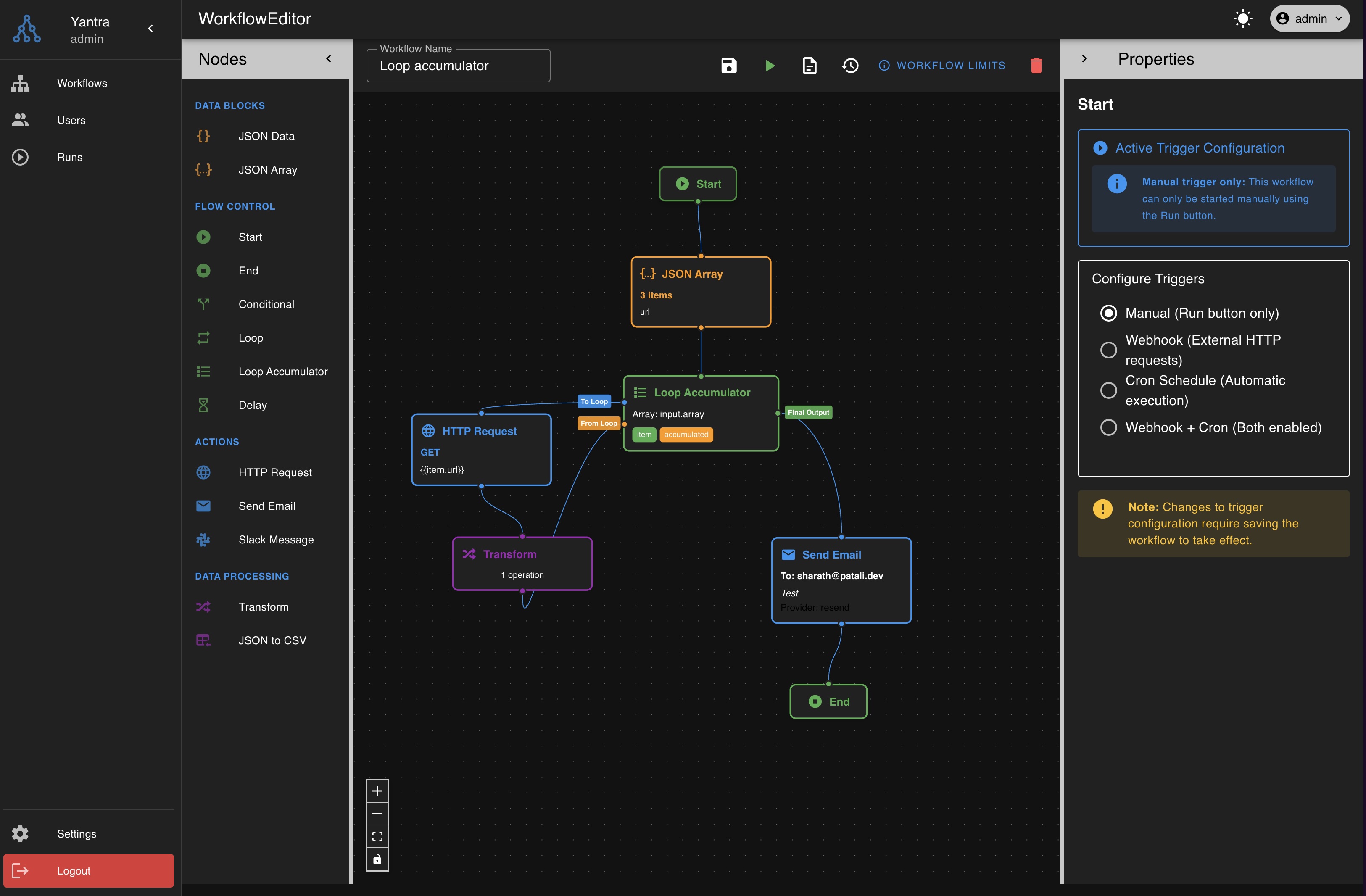
This visual approach makes workflows tangible. A workflow becomes something you can show to a teammate, discuss, and reason about together.
2. The Core Architecture: River and the Outbox Pattern
To build a robust workflow engine, Yantra uses a two-tier architecture:
- River Queue: Orchestrates the overall workflow execution.
- Outbox Pattern: Handles side-effect nodes (like email, Slack) to ensure exactly-once delivery.
2.1 River + PostgreSQL: The Robust Job Queue
Yantra uses River, a PostgreSQL-native job queue. This provides strong guarantees:
-
Transactional Guarantees: Creating a workflow record and queuing the job happen in a single atomic transaction. If one fails, both rollback, preventing lost jobs.
-
Simple Scaling: Workers connect to the same database and compete for jobs. PostgreSQL handles the coordination via the efficient work-stealing queue mechanism:
2.2 The Outbox Pattern: Exactly-Once Delivery
The core challenge is the dual write problem, where a crash and retry cause duplicate side effects (e.g., duplicate email). The Outbox Pattern solves this.
1. Atomic Transaction (The “Write”): The runner saves both the node’s execution record and a pending outbox message in the same transaction.
// All in ONE database transaction
db.Transaction(func(tx *gorm.DB) error {
// 1. Save node execution record
nodeExecution := WorkflowNodeExecution{
ExecutionID: executionID,
NodeID: nodeID,
Status: "success",
Output: outputJSON,
}
tx.Create(&nodeExecution)
// 2. Save outbox message (atomically!)
outboxMessage := OutboxMessage{
EventType: "email.send",
Payload: emailData,
Status: "pending",
ScheduledAt: time.Now(),
}
tx.Create(&outboxMessage)
// If either fails, both rollback
return nil
})
2. Asynchronous Processing (The “Send”): A separate Outbox Worker polls for and processes these pending messages, ensuring the external action is eventually sent.
func (w *OutboxWorker) processMessages(ctx context.Context) {
messages := GetPendingMessages(limit: 10)
for _, msg := range messages {
switch msg.EventType {
case "email.send":
sendEmail(msg.Payload)
case "slack.send":
sendSlackMessage(msg.Payload)
}
// Mark as processed
msg.Status = "processed"
db.Save(&msg)
}
}
This combination is like having two separate mechanisms in your Rube Goldberg machine: one for overall flow (River) and one that ensures critical actions are performed exactly once (Outbox Pattern).
Checkpoint system for when things go wrong
Distributed systems fail. Servers crash. APIs go down. Networks partition. The question isn’t if your workflow will fail, but when - and what you do about it. I’ve built Yantra with multiple layers of retry logic
- Node level
- Workflow level
- Users can also manually restore or retry a workflow.
There’s also a per node checkpoint system so that no node is ever rerun without reason. This is critical as there might be some nodes that are very expensive and we wouldn’t want to be wasteful both of resources, time and money. Since all nodes store the output saved we can just resume a workflow using the checkpoint system.
Yantra’s workflows are DAG’s
Yantra models complex workflows as Directed Acyclic Graphs (DAGs), a crucial design choice that allows it to manage the non-linear nature of real-world automations. A DAG is a collection of nodes (tasks) connected by directed (one-way) edges (data flow) that are acyclic (no loops), ensuring deterministic execution and preventing infinite cycles. This graph structure is essential for representing complex logic like parallel execution (one task triggering multiple simultaneous tasks), conditional branching, and fan-in/fan-out that a simple linear list cannot handle. While DAGs strictly prohibit loops, Yantra accommodates iteration using a Loop Node that preserves the DAG structure by internally unrolling into a safe, sequential (or parallel) execution subgraph, thus maintaining the benefits of a pure DAG—namely, guaranteed termination, determinism, and safe checkpointing. The system traverses this structure using a dependency-resolving approach, akin to Breadth-First Search (BFS), ensuring a node only executes once all its parent nodes have successfully completed and provided their necessary output.
For a deeper dive into Yantra’s architecture and the role of DAGs, you can read more here
The Node Ecosystem
Just like GStreamer has source, transform, and sink elements, Yantra has different node types. Each does one thing well:
Flow control Nodes
- Start Node: Manual trigger point
– Webhook trigger: Triggered by HTTP webhooks
– Cron trigger: Scheduled execution - End Node: Every workflow terminates at an End Node. This is how we detect successful completion
- Conditional Node: Branch based on conditions
- Loop Node: Iterate over arrays
- Loop Accumulator: Collect loop results
- Delay Node: Wait between actions (context-aware!)
Action nodes
- HTTP Node: Makes API requests
- Email Node: Send emails (via outbox pattern)
- Slack Node: Post to Slack channels (via outbox pattern)
Data processing
- Transform Node: JSON data/JSON path operations
- JSON to CSV Node: Convert JSON to CSV format
Data blocks
- JSON: JSON Object Block (for config)
- JSON Array: Array of JSON Objects
Some Real-World Use Cases
The whole point of Yantra was to solve real automation problems. Here are some workflows I’ll be probably using it for :
API Monitoring
Cron (every 5min) → HTTP (health check) → Conditional
├─ (status 200) → End
└─ (status error) → Slack (alert on-call) → Email (send details)
Data Aggregation
Start → HTTP (fetch API 1) ⟍
→ HTTP (fetch API 2) → Transform (merge) → JSON to CSV
→ HTTP (fetch API 3) ⟋ → Email (send report)
Each of these would have been 150+ lines of bash before. Now they’re visual workflows I can build in 5 minutes.
Future Plans: What’s Next
Yantra is work in progress and there’s a lot more I want to do:
1. Clean Up and Open Source
Right now, the codebase has some rough edges:
- Inconsistent error handling patterns
- Some tests need updating
- Documentation needs expansion
- Need to add contribution guidelines
- Add e2e tests
- Security and memory leak tests
My goal is to clean this up and properly open source the project on GitHub. I want others to be able to self-host Yantra, contribute nodes, fix issues and extend it for their own needs.
2. More Triggering mechanism
Hopefully soon:
- Event triggers: Watch for database changes, file uploads, s3 events etc.
- Email triggers: Trigger workflows from incoming email
3. AI Integration
This is the exciting one. LLMs are great at transforming unstructured data into structured data, making decisions based on context, and generating human-readable summaries.
Note: another section where Claude did an excellent job imagining use cases of Yantra!
Imagine nodes like:
AI Transform Node:
{
"prompt": "Extract the customer name, order ID, and complaint type from this email",
"input": "{{previous_node.email_body}}",
"model": "gpt-4"
}
AI Classifier Node:
{
"prompt": "Classify this support ticket as: urgent, normal, or low priority",
"input": "{{ticket.description}}",
"branches": ["urgent", "normal", "low"]
}
AI Generator Node:
{
"prompt": "Write a professional response to this customer complaint",
"input": "{{complaint.text}}",
"tone": "empathetic"
}
This would enable workflows like:
Webhook (support ticket) → AI Classifier → Conditional
├─ (urgent) → AI Generator (draft response) → Slack (notify team)
├─ (normal) → Add to queue
└─ (low) → AI Generator (auto-response) → Email (send to customer)
The outbox pattern is perfect for this - AI API calls are expensive and shouldn’t be duplicated on retries.
4. UI Completeness
Currently the UI Is super rudimentary. It needs someone with better visual eye than me to make it much less industrial :P.
5. Analytics, Cost estimation & Monitoring
I also want to add workflow analytics:
- Success/failure rates
- Average execution time
- Node performance breakdown
- Cost tracking (API calls, execution time)
6. Performance Optimizations
The current architecture scales horizontally (add more workers), but I want to optimize:
- Parallel node execution: Execute independent nodes simultaneously
- Smart caching: Cache HTTP responses, transformation results
- Metrics and observability: Prometheus metrics, OpenTelemetry traces
7. More Node Types (More ideas by Claude. Thanks Mr. Clanker!)
The beauty of Yantra is that nodes are pluggable. We could to add:
- Database nodes: Query PostgreSQL, MySQL, MongoDB directly
- File operations: Read, write, transform files (CSV, JSON, XML)
- Git operations: Clone repos, create commits, open PRs
- Cloud provider nodes: AWS S3, Lambda, EC2; GCP Cloud Functions; Azure Blob Storage
- Container operations: Start Docker containers, run kubectl commands
- Message queue nodes: Publish to RabbitMQ, Kafka, SQS
- Monitoring nodes: Send metrics to Datadog, Prometheus, Grafana
Each node type can be developed independently and shipped as an update.
Closing Thoughts: The Joy of Building
Personally, I’ve been going through a mental block; I hadn’t been interested in building anything outside work. Being frustrated at repeated tasks made me start building on my own. Yantra has liberated me from the rut I was in. I’ve put all my free time into this for the last couple of weeks, and it’s been exhilarating. I know there might be similar solutions, but I wanted to build something that was my own from scratch. With LLMs, it’s super easy to rapidly prototype anything these days. So why not? I know Yantra is useful for my use case; I hope others find it useful as well!
Tech Stack for the Curious
Backend (Go):
- gin-gonic for HTTP routing
- GORM for database ORM
- River for job queuing (PostgreSQL-native)
- robfig/cron for scheduled workflows
Frontend (Vue.js):
- Vue 3 with Composition API
- Vuetify for UI components
- VueFlow for the workflow canvas
- Pinia for state management
- Vite for build tooling
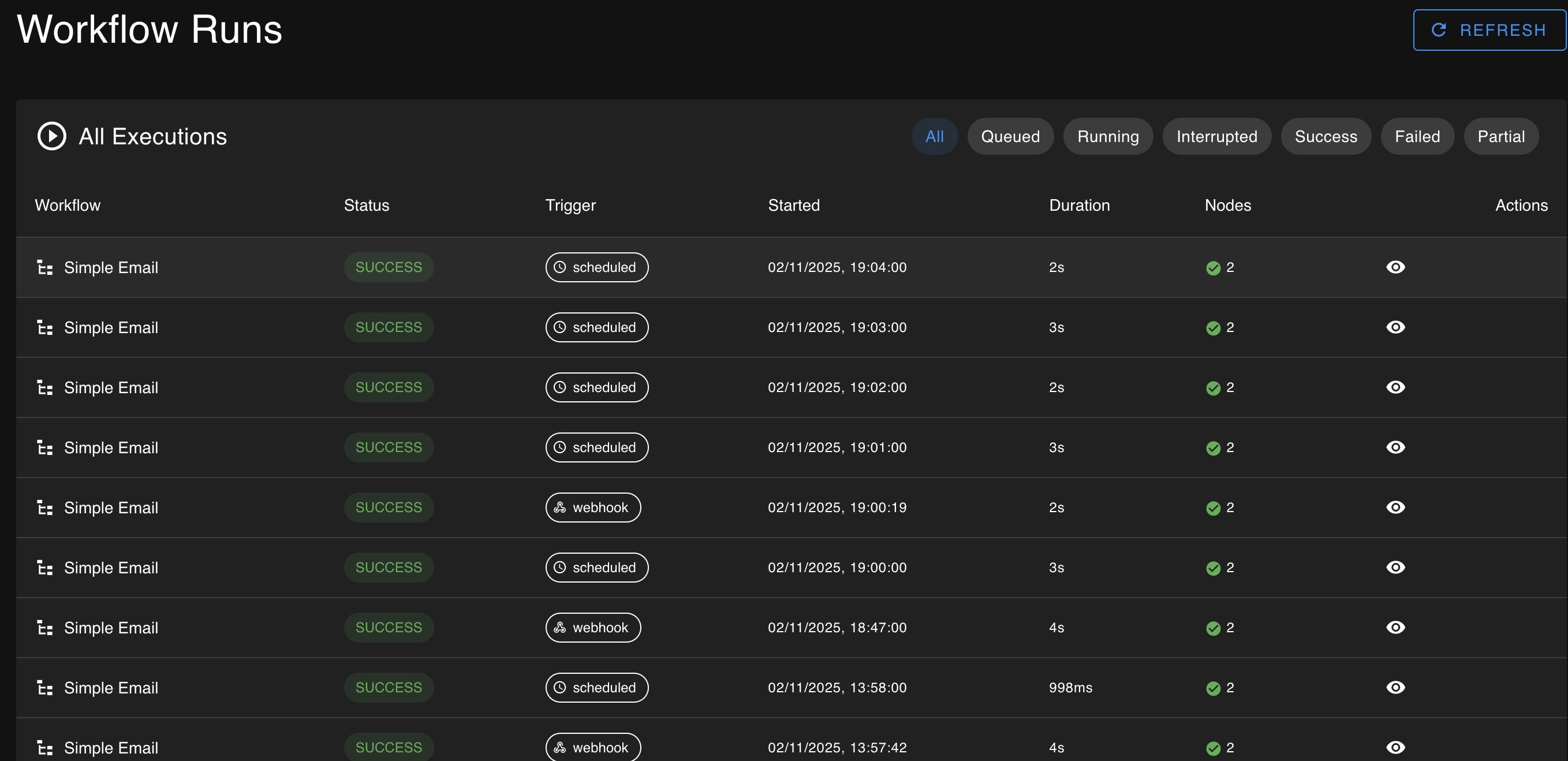
Additional screen shots
A screenshot of the Runs page listing all executions
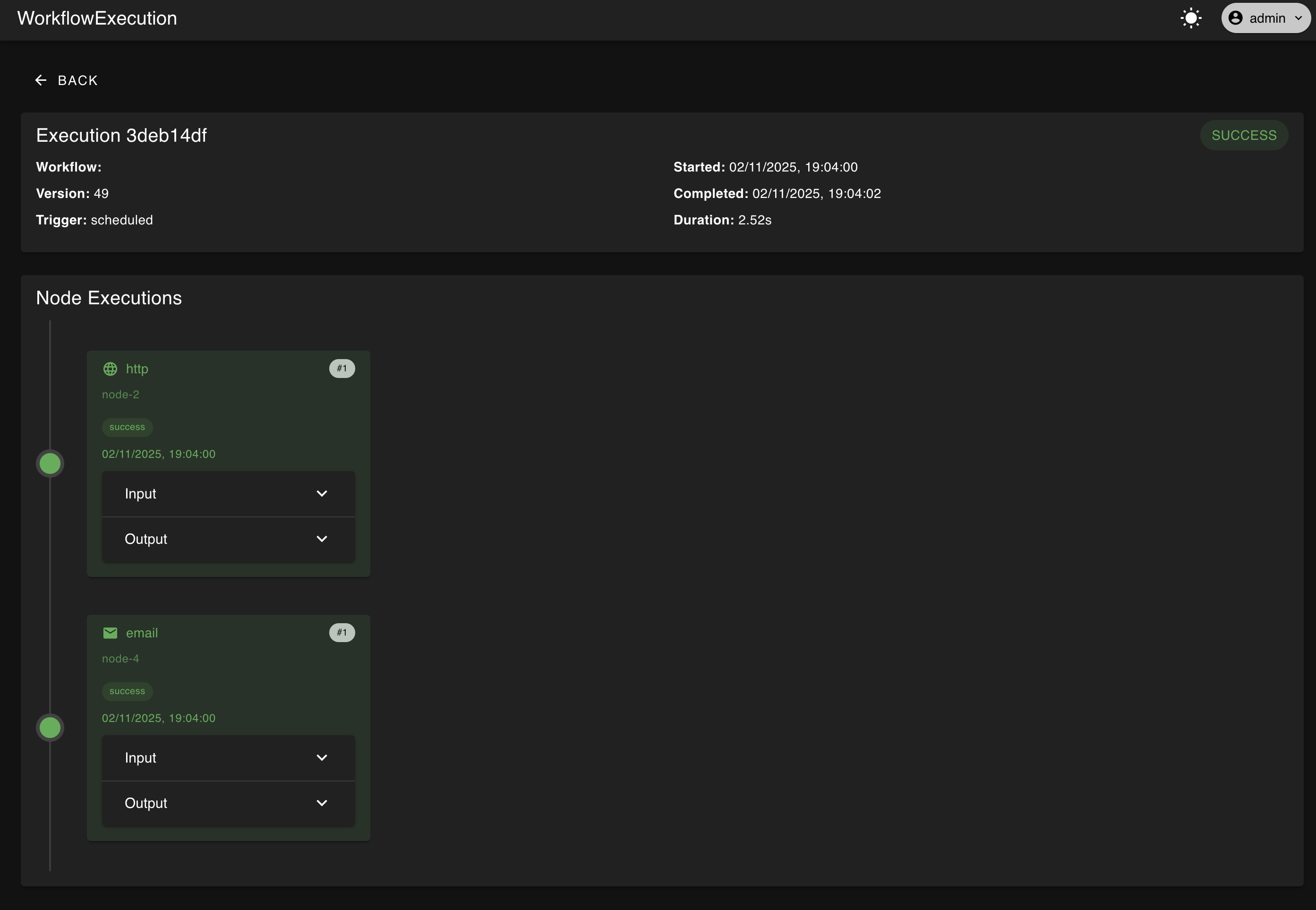
A screenshot of a page showing the node run and order of execution
Yantra is a workflow automation tool built with Go and Vue.js. It features visual workflow building, checkpoint-based resumption, the transaction outbox pattern for reliability, and horizontal scaling with stateless workers.